You route me round-round like a packet...: Why routes should not loop
OpenBSD version: might have helped... or not.
Arch: Any
NSFP: ffs... -.-'
I just had a rather not so fun encounter with the joys of routing loops. Yesterday, already, I saw a bit too many packets running circles in V4LESS-AS:
...
22:38:37.659748 IP6 240e:c2:1800:84:0:1:1:2 > 2a06:d1c3:8ed9:c1fc:448a:114:7fb7:4a79: ICMP6, echo request, id 50599, seq 21853, length 8
22:38:37.659748 IP6 240e:c2:1800:84:0:1:1:2 > 2a06:d1c3:cd62:c1fc:3fe1:a9b:2ef0:f541: ICMP6, echo request, id 27682, seq 53451, length 8
22:38:37.659748 IP6 240e:c2:1800:84:0:1:1:2 > 2a06:d1c3:ab46:c1fc:27d7:6863:2686:949: ICMP6, echo request, id 37253, seq 46574, length 8
22:38:37.659786 IP6 240e:c2:1800:84:0:1:1:2 > 2a06:d1c3:41dd:c4fc:57b5:6e40:3f7:50e8: ICMP6, echo request, id 35591, seq 37275, length 8
22:38:37.659800 IP6 240e:c2:1800:84:0:1:1:2 > 2a06:d1c3:612:c4fc:5019:c1f0:10e4:cf2c: ICMP6, echo request, id 48464, seq 3565, length 8
22:38:37.659810 IP6 240e:c2:1800:84:0:1:1:2 > 2a06:d1c3:8ed9:c1fc:448a:114:7fb7:4a79: ICMP6, echo request, id 50599, seq 21853, length 8
22:38:37.659814 IP6 240e:c2:1800:84:0:1:1:2 > 2a06:d1c3:cd62:c1fc:3fe1:a9b:2ef0:f541: ICMP6, echo request, id 27682, seq 53451, length 8
...
The rather obvious root-cause here is a combination of ‘high TTL’ (255) and ‘somebody’ (read: me) doing stupid things. In this case: having a routing loop.
Making your own routing loop
Routing loops are surprisingly common, and even easier to make yourself.
All you need is two routers that think the corresponding other one is the next
hop for a packet they want to forward. A common way to make that happen would
be, for example, to install the covering prefixes you announce without a
discard or blackhole-like statement.
Drawing from your IGP to find prefixes to route to, your border routers will happily take any packet destined for prefixes not in the IGP on a scenic tour through your AS.
Why this is annoying
Now, as you see up there, there seems to be an address sending a lot of v6 echo requests; My assumption is that this is some form of research work testing a new target generation algorithm for v6.
Well, whatever it is, even with just 8b sized ICMPv6 payloads, this can quickly go to 20mbit on an interface. If your routers route a bit more, it can be a bit more… happily stacking up over time.
After having experienced a bit of looping yesterday (and getting rid of it by making loops go away), I was playing around with what this can do.
Turns out, a single linux box behind a standard end-user access connection can easily ship 5gbit+ on a looping link:
for i in {1..1024}; do sudo ping6 -f -t 255 -s 1452 2001:db8:: & done;
Even a single ping6 -f -t 255 -s 1452 2001:db8:: put ~100mbit on a
single link.
This, of course, is long since known, and has the simple solution of ‘do not have loops in your network’.
While I was playing around, I got a visit from 240e:c2:1800:84:0:1:1:2 again; However, this time in another network, with a bit more ‘loop-capability’:
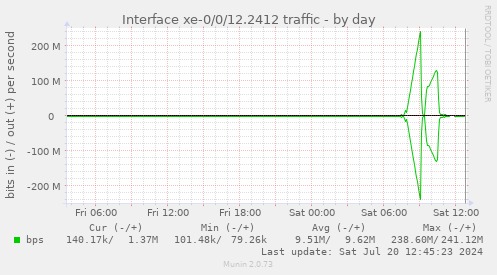
This was, at least, ‘mildly annoying’. Luckily, our friends at 240e:c2:1800:84:0:1:1:2 are just using an 8b payload; Otherwise, I would have had ‘a few’ gbit more on that link.
What to do
Well, obviously, the solution is ‘do not have loops in your network’; In
practice, though, this is often easier said than done (entropy, bodies,
basement… you know). What I ultimately ended up doing for AS59645 was
installing a central iBGP peer running bird that just injects blackhole routes
for each ‘announced prefix -1 bit’ I have (assuming those do not collide with
any other prefix). That way, traffic always finds a way… if only into
/dev/null.
Still, annoying, and probably something to watch out for. -.-‘